Netdata, Prometheus et Grafana : une stack de monitoring simple et puissante

Introduction
Info
Cette documentation contient utilise des versions des logiciels qui peuvent ne pas être les dernières sur le marché. N'oubliez pas de vérifier
Ces derniers temps, j'ai cherché quelques stacks de monitoring simples à mettre en place mais également efficaces avec des métriques pertinentes. Je suis passé par beaucoup de systèmes de monitoring (Check_MK, Sensu, LibreNMS, Shinken...) sans avoir été satisfait. Soit les métriques n'étaient pas pertinentes ; soit l'installation était trop complexe... Bref, il y avait toujours quelque chose qui ne me convenait pas, c'est là que j'ai découvert Netdata, puis peu de temps après, Prometheus et Grafana. Pour bien comprendre ce tutoriel, voici un lexique avec les notions de base :
Lexique
-
Stack : Une stack d'applications est une suite ou un ensemble d'applications qui aident à réaliser une tâche précise.
-
Métrique : Mesure précise d'un composant (logiciel ou matériel), ex : Pourcentage de CPU utilisé à l'instant T...
-
Exporter : Outil qui va récolter les métriques d'un système (CPU utilisé, RAM utilisée...), les traiter et les envoyer à un logiciel.
-
Recolter : Logiciel qui va s'occuper de stocker les métriques envoyées par l'exporter
-
TSDB : Une Time Series Database (TSDB) est une base de données optimisée pour les données horodatées ou les séries chronologiques. Une '"time serie'" est seulement une suite de mesures ou évènements qui sont monitorées, downsampled et agrégées dans le temps.
-
Downsampling : Le downsampling (sous-échantillonnage) est une opération mathématique extrêmement simple permettant de créer un échantillon. Par exemple, si nous avons 60 échantillons de l'utilisation du CPU sur une minute, cela fait 1 par seconde et représente un poids non négligeable, nous pouvons donc faire un downsampling à 12 mesures par minute, nous aurons tout de même une mesure relativement précise avec un poids divisé par 5. Le downsampling rend donc la mesure moins précise mais beaucoup plus légère, nous utilisons donc le downsampling pour les anciennes données pour lesquelles une précision accrue n'est pas nécessaire.
Détail des composants
Netdata
Netdata est un système distribué de monitoring des performances de votre hôte mais également des diverses applications qui y sont installées. Il s'agit d'un agent de surveillance hautement optimisé que nous pouvons installer sur tous vos systèmes et conteneurs.
Il fournit un aperçu en temps réel (grâce à sa granularité de 1s) de tout ce qui se passe sur les systèmes sur lesquels il fonctionne (y compris les serveurs web, les bases de données et les applications), au travers de tableaux de bord interactifs accessibles via son interface web.
Netdata est rapide et efficace, conçu pour fonctionner en permanence sur tous les systèmes (serveurs physiques,virtuels et conteneurs), sans perturber leur fonction principale.
Il s'agit d'un logiciel libre et open-source qui fonctionne actuellement sous Linux, FreeBSD et qui est également accessible sous container Docker.
Prometheus
Prometheus est, dans notre stack, notre TSDB. C'est lui qui va s'occuper de stocker nos données reçues de l'exporter (Netdata) et de les agréger.
Grafana
Depuis de nombreuses années, Grafana est l'outil par excellence de visualisation de données. Grâce à un dashboard totalement personnalisable et de nombreuses sources de données, Grafana s'est donc naturellement imposé dans cette stack de monitoring. Il va s'occuper d'afficher les données récoltées dans Prometheus à notre guise.
Choix généraux
Netdata
Il existe beaucoup d'exporters (Node-Exporter + cAdvisor, Netdata,Telegraf)... pour tout logiciel (HAproxy,NGINX,PHP-FPM)
Cependant, j'ai fait le choix après avoir testé plusieurs exporters d'utiliser Netdata. Ce logiciel intégre des milliers de métriques matériels mais également de nombreuses logiciels (Plugins MySQL, Nginx...) tout ça sans aucune configuration. De plus, Netdata dispose nativement d'un système d'alerte pertinent avec de nombreuses destinations : Slack, Email, Telegram...
Enfin, il s'agit d'un logiciel ne consommant que très peu de RAM et de CPU. Ses métriques sont exportables en quelques clics vers de nombreuses TSDB tels que InfluxDB, Prometheus... Les métriques exportées à Prometheus sont extrêmement claires.
L'avantage comparativement à d'autres exporter est qu'il intègre containers Docker et métriques de l'hôte. Par exemple, pour avoir ces métriques avec un autre exporter, je dois installer Node-exporter + cAdvisor.
Prometheus
J'ai choisi Prometheus en TSDB principalement car il fallait utiliser OpenTSDB en backend en plus de InfluxDB si nous souhaitions utiliser ce dernier avec Netdata. De plus, je trouve le langage de query de Prometheus (PromQL) assez intuitif et puissant.
Installation générale
Installation & configuration de Netdata
2 méthodes pour installer Netdata, soit via image Docker, soit '"à la main'". Pour ma part, j'ai un serveur from scratch et les autres sous Docker, j'ai donc utilisé les 2 méthodes.
Via Docker
Évidemment, il est nécessaire d'avoir une installation Docker à jour. Pour cela, il suffit de suivre les instructions officielles. Une fois cela fait, 2 méthodes de lancement possible : via docker ou docker-compose. Encore une fois, j'utilise compose pour une question de cohérence. Tous mes containers sont ordonnancés dans un fichier docker-compose.yml, les 2 méthodes seront présentées :
Netdata : Running with docker
docker-compose.yml
Et pour le lancer : docker-compose up -d
Dans les 2 cas, il est possible de mettre Netdata derrière un reverse-proxy pour plus de sécurité. Lorsque Netdata est lancé, il sera accessible sur le port 19999 ou via votre reverse-proxy configuré.
Nous verrons par la suite comment monitorer plus précisément nos containers Docker.
From scratch
From scratch, il nous suffira de lancer le script d'installation de netdata qui est très bien fait. La commande indiquée dans le GitHub Netdata est la suivante :
Cette commande installera la base de Netdata sans toutes les dépendances tel que celle nécessaire au plugin MySQL. Pour installer toutes les dépendances nécessaires :
Le paramètre '--dont-wait que l'on peut appliquer à la commande permet de s'abstraire de toutes les questions posées à l'utilisateur.
Installation de Prometheus
Docker
Toujours selon les 2 méthodes, via docker run ou docker-compose :
Prometheus : Running with docker
docker-compose.yml
Warning
Il faut créer manuellement le fichier prometheus.yml sans quoi par défaut Docker considère qu'il s'agit d'un dossier.
From scratch
Même sur un système récent, le binaire de Prometheus est dans une version archaïque (A l'heure actuelle, version 2.7.1 sur Debian Buster datant de début 2019... soit 1 an et demi de retard). Il conviendra donc de télécharger manuellement et de créer l'unit systemd adéquate pour Prometheus. Sur Ubuntu 20.04, le binaire est récent, cependant, je vous conseille tout de même de l'installer manuellement. Il ne faudra donc pas négliger les mises à jours de prometheus et ne pas oublier qu'elles ne seront pas effectuées via votre gestionnaire de packet.
Tout d'abord, rendons-nous sur la page officielle pour trouver la dernière version de Prometheus. A l'heure où j'écris, il s'agit de la 2.40.7.
$ cd ~ ; wget https://github.com/prometheus/prometheus/releases/download/v2.40.7/prometheus-2.40.7.linux-amd64.tar.gz
On extrait les fichiers
On crée notre utilisateur Prometheus :
Puis on déplace les fichiers binaires et de configuration aux endroits prévus :
$ mkdir /etc/prometheus && chown -R prometheus:prometheus /etc/prometheus
$ mv ~/prometheus-2-40.7.linux-amd64/{console*,prometheus.yml} /etc/prometheus
$ mv ~/prometheus-2-40.7.linux-amd64/{prom*,tsdb} /usr/bin/
Dans nos 2 fichiers exécutables, nous avons bien évidemment Prometheus et un fichier nommé Promtool. Ce dernier nous permettra d'interroger directement Prometheus et d'effectuer des opérations avancées.
Et enfin, nous devons faire le fichier de démarrage systemd via le tutoriel disponible. Une fois le fichier créé, il faut l'activer :
Configuration de Prometheus
Toute la configuration Prometheus se fait via le fichier /etc/prometheus/prometheus.yml en syntaxe YAML. Voici la configuration à appliquer :
/etc/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global evaluation_interval.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: node SSL
scheme: https
metrics_path: /api/v1/allmetrics?format=prometheus&source=average
honor_labels: true
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets: [netdata:443]
- targets: [netdata2:443]
- job_name: node
metrics_path: /api/v1/allmetrics?format=prometheus&source=average
honor_labels: true
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets: [netdata:19999]
Afin de ne pas copier coller bêtement la configuration, voici une explication succincte du fichier de configuration :
Premièrement, nous avons un groupe global qui comme son nom l'indique applique les configurations pour tous les jobs. Dedans, nous définissions un temps de scrape toutes les 5 secondes (une minute par défaut) et un reload des règles d'alerting toutes les 5 secondes également.
Deuxièmement, nous avons la directive rule_files qui s'occupe de charger des fichiers YAML où nous pouvons définir des règles d'alerting. Cependant, notre alerting de base est géré via netdata. Nous verrons par la suite comment configurer alertmanager
Troisièmement, la partie la plus importante, nous avons au premier niveau un scrape_configs qui indique la configuration qui sera appliquée par Prometheus. job_name nous indique quel nom appliquer au '"groupe'" au niveau de Prometheus.
Nous avons 2 jobs : Un concernant les noeuds netdata SSL appelé Node SSL et un autre avec les node normaux appelés Node.
Le premier node contient la directive scheme qui nous permet de spécifier que nous souhaitons utiliser une connexion sécurisée TLS pour récupérer les données émises par Netdata. Le second ne contient pas ce keyword car la connexion par défaut est en plain text (http).
Ensuite, nous avons une ligne extrêmement importante, metrics_path. Celle-ci va de paire avec les targets. En targets de static config, nous définissons chaque hôte dont Prometheus doit récupérer les métriques. metrics_path indique donc sur quelle URI Prometheus doit aller récupérer ses métriques. L'URI est propre à chaque exporter. Ainsi, celle-ci est propre à Netdata et nous indique que nous souhaitons des valeurs moyenne au format Prometheus. Toute la documentation sur ce fichier de configuration est disponible ici
Concernant netdata, il est possible d'afficher directement les valeurs bruts récupérées par prometheus à l'adresse suivante : https://netdata.user.domain.tld/api/v1/allmetrics%3Fformat=prometheus&average=yes
Deux helpers netdata sont également disponibles. &types=yes permettant d'afficher le type de métrique renvoyé et &help=yes pouvant vous apporter diverses précisions. Voici un exemple :
Example output of prometheus exporter
# COMMENT netdata_ipv4_tcperrors_packets_persec_average: dimension "RetransSegs", value is packets/s, gauge, dt 1586642036 to 1586642038 inclusive
# COMMENT TYPE netdata_ipv4_tcperrors_packets_persec_average gauge
netdata_ipv4_tcperrors_packets_persec_average{chart="ipv4.tcperrors",family="tcp",dimension="RetransSegs"} 0.0000000 1586642038000
Il est également possible de récuperer d'autres variables système tel que le nombre de sockets TCP supportés... Il suffira d'ajouter &variables=yes au metrics_path.
Selon le panel grafana que vous trouvez, vous pouvez trouver des unités en MB au lieu d'en MiB. Ce comportement a changé en netdata 1.12, pour retrouver les anciennes unités, rajouter &oldunits=yes ) à votre metrics_path.
Pour vérifier que tout est conforme, rendez-vous dans l'interface de Prometheus (Par défaut, port 9090), vous devriez tomber sur cette page :
On se rend ensuite sur Status puis Target

Si tout est bon, vous devriez apercevoir vos différentes targets avec l'état UP.
Syntaxe Prometheus
Prometheus se base sur une syntaxe intuitive nommée PromQL. Nous pouvons nous exercer à la syntaxe PromQL depuis le menu principal de Prometheus.
Il est possible de tester la syntaxe de PromQL depuis la page d'accueil de Prometheus.
A côté du bouton Execute nous avons // - insert metric at cursor - //. Ceci nous permet de voir toutes les métriques disponibles via Prometheus.
Les métriques de Netdata sont également disponibles via l'URL de notre Grafana suivi du chemin de la métrique.
Voici un exemple de relevé :
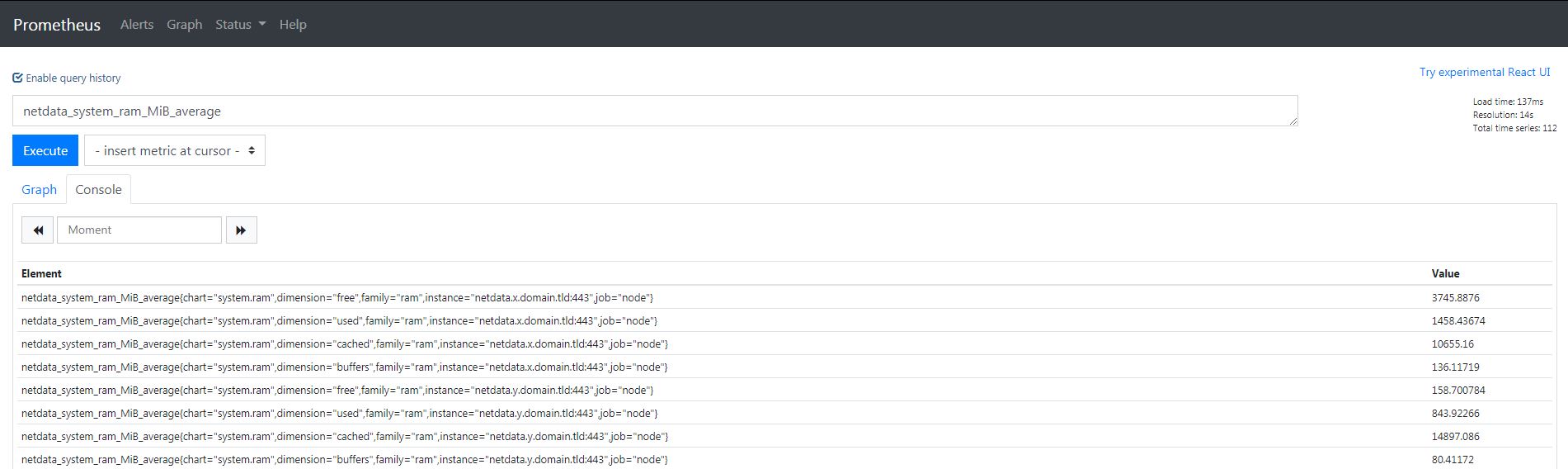
Comme vous pouvez le voir, nous obtenons de nombreuses informations (Concrètement, on obtient en réponse tous les netdata que nous monitorons).
Décortiquons une réponse type pour un serveur :
Example output of netdata exporter
netdata_system_ram_MiB_average{chart="system.ram",dimension="free",family="ram",instance="netdata.x.domain.tld:443",job="node"}
netdata_system_ram_MiB_average{chart="system.ram",dimension="used",family="ram",instance="netdata.x.domain.tld:443",job="node"}
netdata_system_ram_MiB_average{chart="system.ram",dimension="cached",family="ram",instance="netdata.x.domain.tld:443",job="node"}
netdata_system_ram_MiB_average{chart="system.ram",dimension="buffers",family="ram",instance="netdata.x.domain.tld:443",job="node"}
Il existe un site internet proposant quelques règles Prometheus. Attention, celles-ci ne sont pas forcément optimsiées ou fonctionnelles.
En premier lieu, nous observons que nous avons 4 métriques différentes pour le même serveur. Ce qui est contenu dans les accolades est une variable pour Prometheus. Par exemple, voici comment obtenir la RAM utilisée pour le serveur ci-dessus :
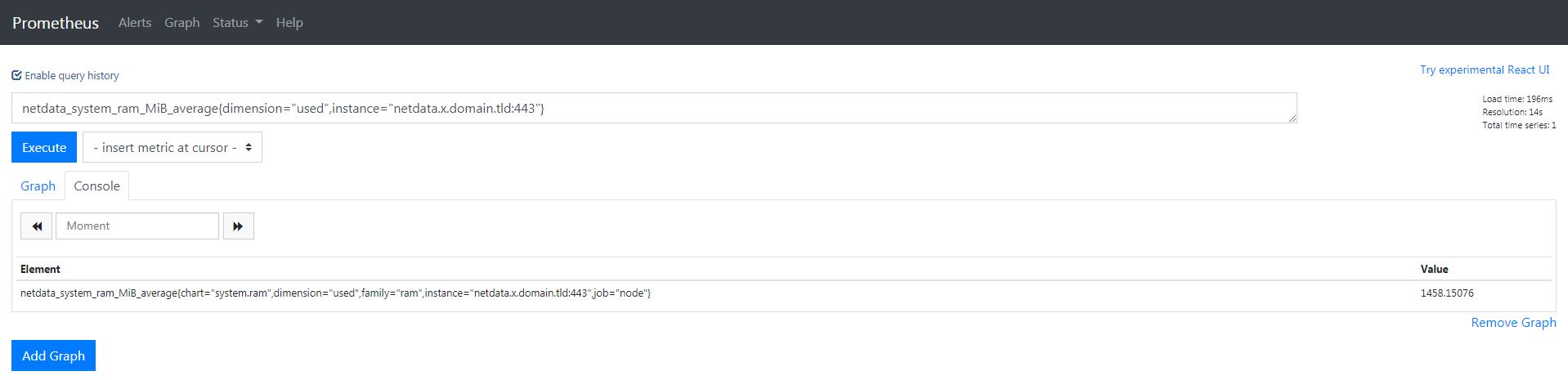
Comme nous pouvons le voir, nous nous sommes servis des variables de Prometheus pour filtrer ce que nous voulons. Nous pouvons également nous servir de ces variables pour obtenir des graphiques dynamiques sur Grafana.
Installation de Grafana
Docker
docker-compose.yml
From scratch
Grafana n'étant toujours pas disponible dans les dépôts de Debian 10, nous devons donc ajouter ses propres dépôts avant de pouvoir l'installer :
$ sudo apt-get install -y apt-transport-https
$ echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
$ wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
$ apt update && apt install -y grafana
Une fois installé, Grafana n'est pas démarré et n'est pas lancé au démarrage de votre serveur. Pour cela voici les commandes :
Utiliser Prometheus en Datasource
Une fois toute la stack installée, nous devons configurer Grafana afin qu'il utilise Prometheus comme source de données. Par défaut, Grafana écoute sur le port 3030 et ses identifiants par défauts sont admin / admin.
Il faut alors cliquer sur Add Data Sources :
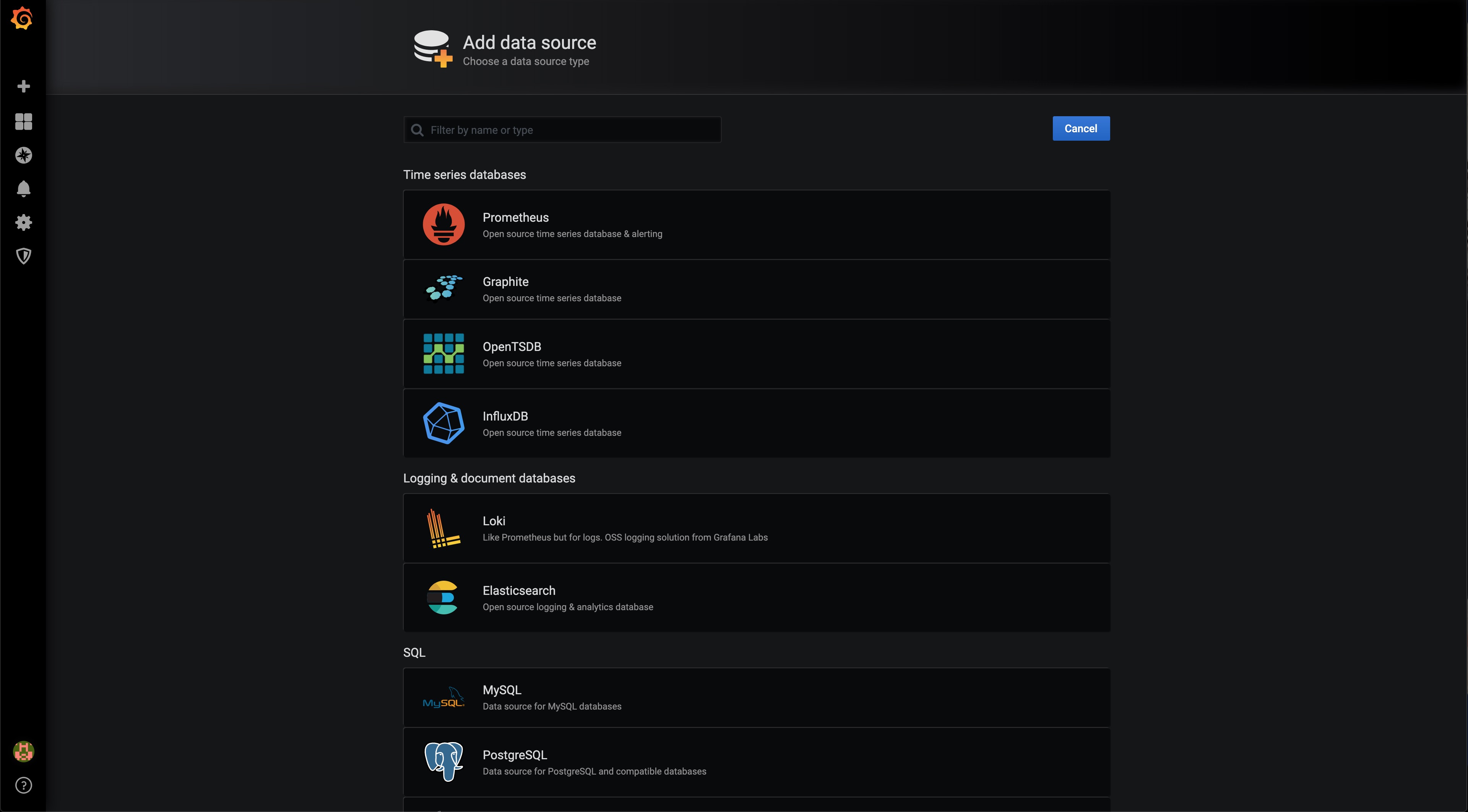
Dans le choix de la Data Source, nous choisissons bien évidemment Prometheus :
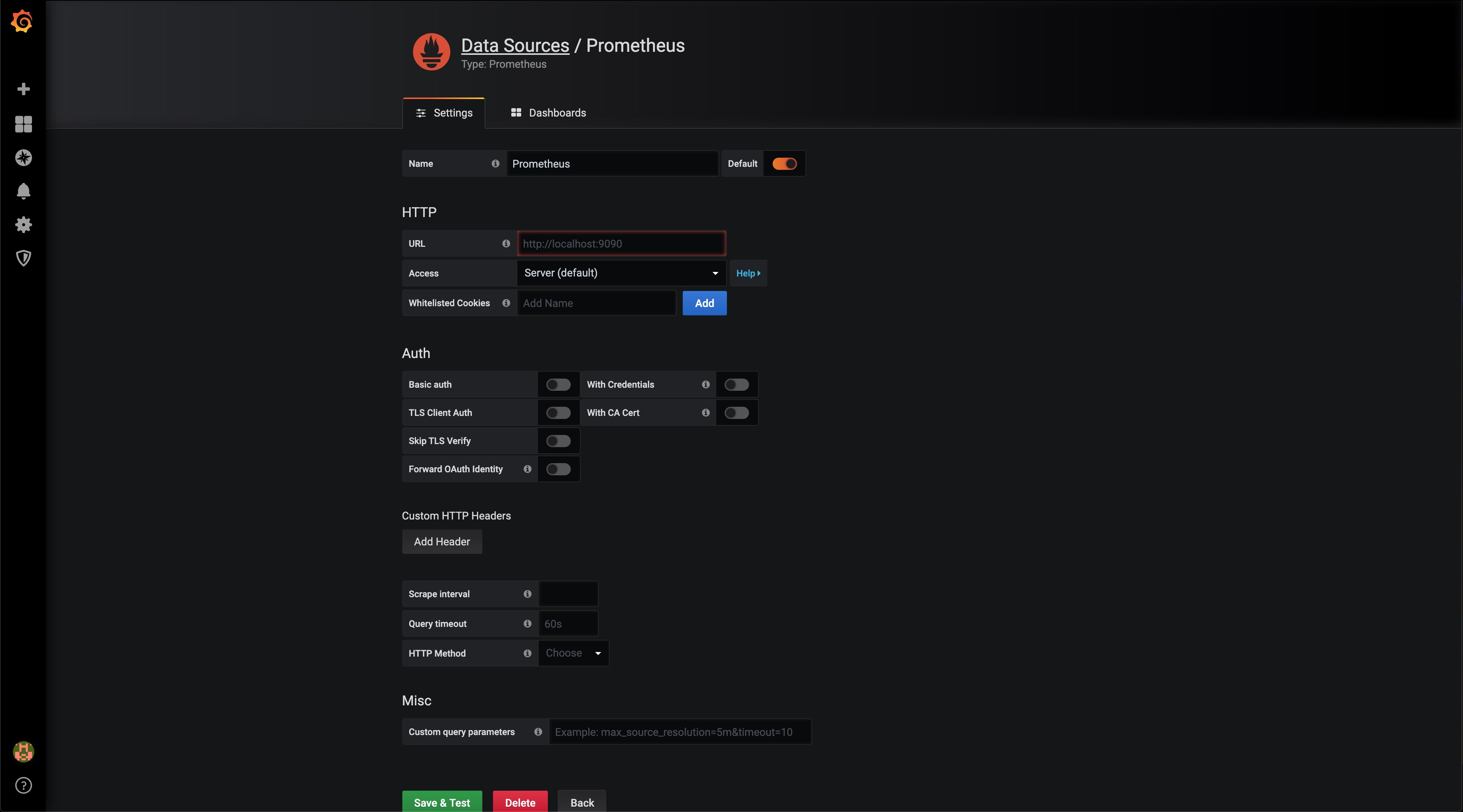
Ici, les choses se corsent un tout petit peu.
Tout d'abord, en URL, 3 cas sont possibles :
- Si vous avez installé Prometheus et Grafana sur le même serveur, alors vous pouvez pointer directement vers Prometheus : http://localhost:9090
- Si votre Prometheus n'est pas sur le serveur de Grafana, alors il vous faudra y accéder via son IP : http://ip:port
- S'il est derrière un reverse-proxy (la solution optimale), alors il faudra y accéder de la manière suivante : https://domain.tld
Une fois ceci fait, Save & Test
Si tout est correct, voici le message que vous obtiendrez :

Félicitations, une étape fastidieuse est passée, cependant, le plus dur reste à faire, la création de votre premier panel !
Création de son premier panel
Créer son panel Grafana peut s'avérer fastidieux. De nombreuses options sont possibles. Pour vous faciliter sa prise en main, Grafana vous mets à disposition une instance test. Malheureusement, la syntaxe utilisée pour l'instance est du InfluxQL et non du PromQL
Grafana est un système extrêmement personnalisable, c'est pour cela que je vais vous partager mes panels.
Mes panels Grafana

Lien de téléchargement : ici

Lien de téléchargement : ici
Lien de téléchargement : ici
La communauté Grafana met à votre disposition énormement de dashboards
Trucs & Astuces
Grafana
L'utilisation de Grafana est assez simple. Cependant, certaines choses sont assez mal conçues, il faut les découvrir par soi-même. Je mettrai cette partie à jour au fur et à mesure de mes découvertes.
Lecture d'un timestamp
Pour lire une métrique de type Unix Timestamp, également appelé Epoch (nombre de secondes écoulées depuis le 1er Janvier 1970), il faut multiplier par 1000 la valeur et lui appliquer n'importe quel filtre de type Date. En effet, comme me l'a expliqué Olivier sur LinkedIn, il s'agit d'une interface écrit en JavaScript. Le timestamp renvoyé par prometheus est en seconde et celui de JS est exprimé en millisecondes, c'est pour cela qu'il faut multiplier par 1000.
Prometheus
Pour apporter une sécurité supplémentaire, il faut faire écouter Prometheus sur localhost uniquement. Pour cela, dans votre unit systemd, il faudra rajouter l'argument --web.listen-address="127.0.0.1:9090" sans oublier de relancer le service Prometheus ainsi que de faire le reverse-proxy adéquate.
Pour vérifier que notre modification a bien été prise en compte, il suffit de faire un ss -laptn sport eq 9090 et de constater que la Local Address est bien 127.0.0.1.
Si votre instance Prometheus n'est pas sur le même serveur et que Grafana/Prometheus ne sont pas joignables via un réseau privé, alors il vous faudra un reverse-proxy avec authentification basic
Petit reverse proxy pour Prometheus, à adapter pour votre setup :
nginx-prometheus.conf
upstream prometheus {
server localhost:9090;
}
server {
listen 80;
listen [::]:80;
server_name prometheus.domain.tld;
access_log off;
include snippets/letsencrypt.conf;
location / {
return 301 https://prometheus.domain.tld$request_uri;
}
}
server {
server_name prometheus.domain.tld;
auth_basic "prometheus";
auth_basic_user_file /etc/nginx/.htpasswd;
listen 443 ssl;
listen [::]:443 ssl;
http2 on;
ssl_certificate /root/.acme.sh/prometheus.domain.tld_ecc/fullchain.cer;
ssl_certificate_key /root/.acme.sh/prometheus.domain.tld_ecc/prometheus.domain.tld.key;
location / {
proxy_set_header Host $http_host;
proxy_pass http://prometheus;
}
}
Netdata
Général
Comme dit précédemment, Netdata permet nativement d'exporter de nombreuses métriques. Cependant, pour certaines d'entre elles, dont MySQL, il est nécessaire de faire une manipulation :
mysql> CREATE USER netdata@localhost;
mysql> GRANT USAGE ON *.* TO netdata@localhost;
mysql> FLUSH PRIVILEGES;
Il faut également avoir installé netdata avec toutes ses dépendances via la commande d'installation.
Docker
Résolution des noms des containers
Pour résoudre les noms des containers dockers afin de ne pas avoir une suite de chiffres et lettres incompréhensible, plusieurs méthodes s'offrent à nous.
Tout d'abord, nous pouvons exposer l'API Docker via un autre container afin de contrôler complètement son comportement :
docker-compose.yml
La variable d'environnement CONTAINERS=1 nous permet d'indiquer à Netdata qu'il n'a accès qu'à la partie de l'API concernant les containers, ce qui peut être très utile en cas de compromission du container.
La seconde manière de faire est d'indiquer à Netdata de s'exécuter en tant que groupe Docker, pour cela, un simple grep docker /etc/group '| cut -d ':' -f 3 nous permet de récupérer le groupe docker (généralement 999 avant Debian 10 et 998 avec Debian 10) et nous ajoutons la variable d'environnement PGID=998 à notre container netdata.
Enfin, troisième et dernière possibilité que je déconseille fortement est de lancer Netdata en tant qu'utilisateur root via la variable d'environnement DOCKER_USR=root sur notre container.
Monitoring d'un mountpoint personnalisé
Pour monitorer les I/O, espace disque... d'un point de montage, il faut bien évidemment l'indiquer en volume sur votre container Netdata.
Prenons un exemple simple. Si vous avez différents utilisateurs dans votre /home (jeremy, augustin...) alors il faudra faudra ajouter le volume /home à votre container.
La base d'une stack de monitoring est désormais acquise.
Pour aller plus loin
Il s'agit d'une stack très simple à mettre en place. Cependant, celle-ci n'est pas parfaite, nous n'avons aucune indication concernant nos sites web, l'état des certificats SSL, ou encore aucun alerting.
Rendre Prometheus dynamique
Actuellement, nous avons une configuration statique, ce qui implique un redémarrage de prometheus à chaque ajout/suppression d'un host. Le redémarrage de prometheus peut durer plusieurs minutes avec la reprise des WAL...
A la place de static_configs, il est donc possible d'utiliser d'autres directives, dont file_sd_configs. Votre configuration prometheus sera donc dynamique via un simple fichier json que prometheus relira à chaque modification, qu'il s'agisse d'une suppression ou d'un ajout.
Remplacer le bloc node de votre fichier prometheus.yml par le suivant :
/etc/prometheus/prometheus.yml
Si vous avez bien suivi notre tutoriel sur la création d'une unit systemd, vous avez compris que nous n'avons pas besoin de spécifier un chemin absolu via la directive WorkingDirectory. Cependant, pour un soucis de clareté, je préfère indiquer un chemin absolu.
Comme vous pouvez vous en douter, le fichier netdata.json contiendra les différents nodes à monitorer. Si vous souhaitez ajouter/supprimer un fichier ou un job, il vous faudra évidemment redémarrer Prometheus. Voici le contenu dudit fichier :
/etc/prometheus/netdata.json
Ce fichier est simplissime. Nous avons les labels dans un premier bloc puis nos différentes targets. Attention à penser aux virgules entre les targets et à ne pas en mettre à votre dernière, sans quoi votre JSON serait invalide.
Une fois ceci fait, nous redémarrons une ultime fois Prometheus systemctl restart prometheus, puis nous pourrons modifer à chaud nos targets sans aucune autre modification, plutôt pratique ! D'autres manières sont également possibles pour importer dynamiquement vos targets par exemple via consul. J'ai choisi ce mode-ci car il me convient parfaitement. Xavier Pestel (xavki) nous propose une excellente vidéo pour l'inventaire dynamique via Consul.
Monitorer vos certificats & websites
Le monitorer de ces éléments n'est pas proposé nativement par notre exporter Netdata. Heureusement, Prometheus à pensé à tout et nous propose blackbox_exporter, un exporter orienté autour des tests HTTP, ICMP & co. Pour l'installer, nous devons procéder de la même manière que Prometheus. Si vous disposez de Prometheus sur votre machine, il n'y a aucun intérêt à créer un utilisateur supplémentaire, vous pourrez lancer blackbox_exporter en tant que Prometheus et placer son fichier de configuration dans le répertoire de Prometheus.
Il faut toujours se rendre sur la page Github afin de s'assurer que nous disposons de la dernière version de notre logiciel :
$ cd ~ ; wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.24.0/blackbox_exporter-0.24.0.linux-amd64.tar.gz
Et on extrait toujours les fichiers :
Et on les déplace dans le dossier adéquate. Attention à bien mettre le bon username (prometheus ou celui que vous aurez décidés)
$ mkdir /etc/blackbox && chown -R prometheus:prometheus /etc/blackbox
$ mv ~/blackbox_exporter-0.24.0.linux-amd64/blackbox_exporter /usr/bin
$ mv ~/blackbox_exporter-0.24.0.linux-amd64/blackbox.yml /etc/blackbox
Si nous souhaitons utiliser le test ICMP de blackbox et que nous avons lancé blackbox en tant que non-root, alors il nous faudra ajouter une Capability à notre unit.
Nous n'oublions également pas que le paquet puisse effectuer les opérations dont il a besoin :
Sans quoi, nous recevrons une erreur selon laquelle nous n'avons pas la permission d'effectuer cette action :
ts=2020-04-06T01:59:18.302197375Z caller=main.go:119 module=icmp target=netdata.pierre.x.eu level=error msg="Error listening to socket" err="listen ip4:icmp 0.0.0.0: socket: operation not permitted"
Les tests écrits par défaut par les mainteneurs de Blackbox nous conviendront pour faire de simples tests de chargement de page web ainsi que d'ICMP, nous ne toucherons donc pas à ce fichier.
Maintenant que Blackbox est correctement installé, nous devons indiquer à Prometheus d'aller récupérer les métriques de Blackbox :
Target for prometheus.yml
- job_name: HTTP
scheme: http
params:
module: [http_2xx]
metrics_path: /probe
file_sd_configs:
- files:
- http.json
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: localhost:9115 # Blackbox exporter.
Ce job diffère un tout petit peu des anciens, tout d'abord, nous devons spécifier un module correspondant au nom de notre module dans blackbox.yml. Nous avons besoin de passer la destination de notre test à Blackbox. Pour cela, nous utilisons le module relabel_configs de Prometheus. Enfin, nous réécrivons la variable address avec la valeur de notre exporter Blackbox, dans notre cas, localhost:9115. Voici le contenu de notre fichier http.json
/etc/prometheus/http.json
Une fois cette étape faite et Prometheus redémarré, nous avons accès de nouvelles métriques sur Prometheus (en fonction du module choisi, il s'agit ici des métriques pour le module http_2xx) :
Output of blackbox_exporter / http_2xx
probe_dns_lookup_time_seconds 0.001002382
probe_duration_seconds 0.102398015
probe_failed_due_to_regex 0
probe_http_content_length 89715
probe_http_duration_seconds{phase="connect"} 0.022205535
probe_http_duration_seconds{phase="processing"} 0.022529847
probe_http_duration_seconds{phase="resolve"} 0.006274033
probe_http_duration_seconds{phase="tls"} 0.038470116
probe_http_duration_seconds{phase="transfer"} 0.021751707
probe_http_redirects 1
probe_http_ssl 1
probe_http_status_code 200
probe_http_uncompressed_body_length 89715
probe_http_version 1.1
probe_ip_protocol 4
probe_ssl_earliest_cert_expiry 1.59282791e+09
probe_success 1
probe_tls_version_info{version="TLS 1.3"} 1
Comme vous pouvez le voir, nous avons de nombreuses métriques, particulièrement 2 plus utiles que les autres :
probe_successnous indique si le test s'est effectué correctementprobe_http_status_codenous renvoie le code de retour de la pageprobe_ssl_earliest_cert_expirynous renvoie la date d'expiration (sous forme de timestamp)
Grace à ces nouvelles métriques, vous pouvez indiquer l'état de services dans vos dashboards Grafana, la date d'expiration de vos certificats... Un autre exporter s'occupant uniquement de la partie SSL/TLS, mais fournissant plus de verbosité est disponible. Il se nomme node-cert-exporter, je lui préfère blackbox_exporter car il est plus polyvalent et supervise une URL, non un chemin vers un certificat. Cependant, celui-ci peut être intéressant dans le cas de supervision de certificats pour des systèmes comme Kubernetes ou autre.
Intégration d'un système d'alerting
Alertmanager
Alertmanager est la brique d'alerting de notre stack, celle-ci se greffe directement à prometheus. La procédure d'installation reste la même que tous les autres produits créés par Prometheus :
Rendons-nous sur la page officielle pour trouver la dernière version de alermanager . A l'heure où j'écris, il s'agit de la 0.20.0.
$ cd ~ ; wget https://github.com/prometheus/alertmanager/releases/download/v0.25.0/alertmanager-0.25.0.linux-amd64.tar.gz
On extrait les fichiers
cette archive contient, comme les autres, des exécutables et un fichier de configuration, nous les déplaçons dans le répertoire adéquat. Encore une fois, si nous avons déjà Prometheus, nous mettrons le fichier de configuration dans ce répertoire, sinon, nous créerons le répertoire /etc/alertmanager
$ mv ~/alertmanager-0.25.0.linux-amd64/{amtool,alertmanager} /usr/bin/
$ mv ~/alertmanager-0.25.0.linux-amd64/alertmanager.yml /etc/alertmanager
$ chown -R prometheus:prometheus /etc/alertmanager
Pour créer l'unit, je vous renvoie une nouvelle fois vers le tutoriel adéquat. Amtool est un outil permettant d'interagir directement avec l'API de AlertManager.
alertmanager.yml
Voici le contenu par défaut du fichier alertmanager.yml :
/etc/prometheus/alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: web.hook
receivers:
- name: web.hook
webhook_configs:
- url: http://127.0.0.1:5001/
inhibit_rules:
- source_match:
severity: critical
target_match:
severity: warning
equal: [alertname, dev, instance]
Nous voyons ici une directive route qui nous indique comment chaque alerte sera traitée par alertmanager, nous pouvons faire plusieurs directives route si nous souhaitons des traitements spécifiques. Chaque route est définie par un receiver unique.
Tout d'abord, la directive group_by. Celle-ci prend un tableau en paramètre. Par défaut, il contient alert et instance ce qui nous indique que les alertes contenant ces tags seront traitées de la même manière. Nous n'utilisons qu'une route et souhaitons obtenir toutes les alertes, nous utilisons donc le tag alertname.
Ensuite, group_wait est ici défini à 10 secondes. Il s'agit du nombre de secondes avant qu'une alerte d'un nouveau groupe soit envoyé si vous disposez de plusieurs groupes. Comme nous ne disposons que d'un seul groupe, il s'agit d'une valeur arbitraire ici définie à 10s.
group_interval est défini à 10s ce qui signifie que les autres notifications concernant le même groupe arriverons toutes les 10s.
La variable repeat_interval est le délai à attendre si les alertes que nous avons eu ne sont toujours pas résolues. Ll s'agit encore d'une valeur arbitraire que nous définissons à une heure.
De nombreux receivers sont possibles, adresse mail, slack, webhook... Dans mon cas, j'ai choisi d'utiliser un Webhook qui va s'occuper d'envoyer mes notifications sur Telegram. Ce webhook écoutera donc sur le port 8080 et non sur le 5001, il s'agit ici de la dernière valeur à modifier. Pour plus d'informations, je vous invite à aller voir l'exemple officiel d'alertmanager.
Modifications du fichier prometheus.yml
Faisons un petit point sur ce à quoi ressemble notre prometheus.yml à ce stade-là. Nous voyons une partie concernant les règles (rule_files) mais nous n'y avons pas touché. Nous allons donc charger notre première règle. De plus, il faudra indiquer à Prometheus de renvoyer ses alertes à alertmanager.
/etc/prometheus/prometheus.yml
Nous indiquons ici à Prometheus d'utiliser comme règles le contenu du fichier alert.rules.yml mais également d'envoyer les alertes vers la target de type alertmanager disponible sur 127.0.0.1:9093.
alert.rules.yml
/etc/prometheus/alert.rules.json
groups:
- name: alert.rules
rules:
- alert: EndpointDown
expr: probe_success == 0
for: 10s
labels:
severity: "critical"
annotations:
summary: "Endpoint {{ $labels.instance }} has an issue"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 10 seconds."
La syntaxe est assez compréhensible. Tout d'abord, nous définissons un nom au groupe de règles puis nous définissons la règle. Celle-ci va se nommer EndpointDown. L'expression ici probe_success == 0 (métrique renvoyée blackbox_exporter) vérifie si l'URL monitorée par blackbox_exporter est up ou down pendant 10 secondes. Les variables définies dans l'annotations sont définies par Prometheus.
Pour vérifier que notre règle est bien prise en place, nous ferons la commande suivante :
$ promtool check rules /etc/prometheus/alert.rules.yml
Checking /etc/prometheus/alert.rules.yml
SUCCESS: 1 rules found
Voici d'autres exemples de règles Prometheus trouvées sur le web :
/etc/prometheus/alert.rules.yml
groups:
- name: alert.rules
rules:
- alert: node_high_cpu_usage_70
expr: avg(rate(netdata_cpu_cpu_percentage_average{dimension="idle"}[1m])) by (job) > 70
for: 1m
annotations:
description: {{ $labels.job }} on {{ $labels.job }} CPU usage is at {{ humanize $value }}%.
summary: CPU alert for container node {{ $labels.job }}
- alert: node_high_memory_usage_70
expr: 100 / sum(netdata_system_ram_MB_average) by (job)
* sum(netdata_system_ram_MiB_average{dimension=~"free|cached"}) by (job) < 30
for: 1m
annotations:
description: {{ $labels.job }} memory usage is {{ humanize $value}}%.
summary: Memory alert for container node {{ $labels.job }}
- alert: node_low_root_filesystem_space_20
expr: 100 / sum(netdata_disk_space_GiB_average{family="/"}) by (job)
* sum(netdata_disk_space_GB_average{family="/",dimension=~"avail|cached"}) by (job) < 20
for: 1m
annotations:
description: {{ $labels.job }} root filesystem space is {{ humanize $value}}%.
summary: Root filesystem alert for container node {{ $labels.job }}
- alert: node_root_filesystem_fill_rate_6h
expr: predict_linear(netdata_disk_space_GiB_average{family="/",dimension=~"avail|cached"}[1h], 6 * 3600) < 0
for: 1h
labels:
severity: critical
annotations:
description: Container node {{ $labels.job }} root filesystem is going to fill up in 6h.
summary: Disk fill alert for node {{ $labels.job }}
Enormement d'exemples sont disponibles ici
Bot Telegram Alertmanager
Pour avoir nos alertes sur Telegram, j'utilise le bot de metalmatze qui répond juste à nos besoins. Dernière version au jour de l'écriture de cet article : 0.4.3
$ cd ~ ; wget https://github.com/metalmatze/alertmanager-bot/releases/download/0.4.3/alertmanager-bot-0.4.3-linux-amd64
$ mv alertmanager-bot-0.4.3-linux-amd64 /usr/bin/alertmanager-bot && chmod +x /usr/bin/alertmanager-bot
Encore une fois, on n'oublie pas d'écrire l'unit file qui va bien, nous avons l'habitude désormais. Il nous faudra créer un bot telegram et relever notre ChatID.
Notre directive ExecStart de notre unit sera la suivante :
ExecStart=alertmanager-bot --store=bolt --telegram.token=BOT_TOKEN --telegram.admin=USER_ID --template.paths=default.tmpl
Penser bien à remplacer BOT_TOKEN et USER_ID par les bonnes variables. Quand au template default.tpl, voici celui que j'utilise :
Template alertmanager
{{/* Alertmanager Silence link */}}
{{ define "__alert_silence_link" -}}
https://alertmanager.dynfactory.com/#/silences/new?filter=%7B
{{- range .CommonLabels.SortedPairs -}}
{{- if ne .Name "alertname" -}}
{{- .Name }}%3D"{{- .Value | urlquery -}}"%2C%20
{{- end -}}
{{- end -}}
alertname%3D"{{- .CommonLabels.alertname -}}"%7D
{{- end }}
{{/* Severity of the alert */}}
{{ define "__alert_severity" -}}
{{- if eq .CommonLabels.severity "critical" -}}
*Severity:* :no_entry:
{{- else if eq .CommonLabels.severity "warning" -}}
*Severity:* :warning:
{{- else if eq .CommonLabels.severity "info" -}}
*Severity:* :information_source:
{{- else -}}
*Severity:* :question: {{ .CommonLabels.severity }}
{{- end }}
{{- end }}
{{/* Title of the Slack alert */}}
{{ define "slack.title" -}}
[{{ .Status | toUpper -}}
{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{- end -}}
] {{ .CommonLabels.alertname }}
{{- end }}
{{/* Color of Slack attachment (appears as line next to alert )*/}}
{{ define "slack.color" -}}
{{ if eq .Status "firing" -}}
{{ if eq .CommonLabels.severity "warning" -}}
warning
{{- else if eq .CommonLabels.severity "critical" -}}
danger
{{- else -}}
#439FE0
{{- end -}}
{{ else -}}
good
{{- end }}
{{- end }}
{{/* The text to display in the alert */}}
{{ define "slack.text" -}}
{{ template "__alert_severity" . }}
{{ range .Alerts }}
{{- if .Annotations.summary }}
{{- "\n" -}}
*Summary:* {{ .Annotations.summary }}
{{- "\n" -}}
{{- end }}
{{- if .Annotations.description }}
{{- "\n" -}}
{{ .Annotations.description }}
{{- "\n" -}}
{{- end }}
{{- if .Annotations.message }}
{{- "\n" -}}
{{ .Annotations.message }}
{{- "\n" -}}
{{- end }}
*Details:*
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}`
{{ end }}
{{- end }}
{{- end }}
Stockage très longue durée
Prometheus n'est pas adapté au stockage sur une longue durée de nos métriques. Il nous faudra alors utiliser VictoriaMetrics ou Thanos. Je n'ai pas pu explorer ces deux logiciels, n'ayant des métriques que sur une courte durée.
L'avantage de VictoriaMetrics nous concernant est qu'il utilise le système PromQL comme Prometheus, nous n'aurons donc pas à apprendre un nouveau langage.
Il pourra s'agit d'une piste d'enrichissement de ce tutorial dans le futur avec l'intégration de VictoriaMetrics.
De plus, VictoriaMetrics n'est pas un système monolithique comme l'est Prometheus, chaque fonctionnalité est un binaire distinct ce qui permet de scale simplement sur un cluster Kubernetes ou autre
Exporters
Voici une liste d'exporter pour divers équipements/logiciels. Cependant, je n'ai pas testé ces derniers :
| Matériel/Logiciel | Lien |
|---|---|
| JunOS | JunOS |
| Cisco | Cisco |
| Mikrotik | Mikrotik |
| Windows | WMI |
| VMWare | VMWare |
| Proxmox | Promxox |
| CloudFlare | CloudFlare |
Une liste officielle de tous les exporters Prometheus officielle est disponible, vous permettant de choisir l'exporter qu'il vous faut
Conclusion
J'ai pris plaisir à écrire cet article malgré sa complexité et sa longueur. Creuser à travers toutes les documentations et autres sources a été un vrai plaisir.
Toutes les formes de configuration n'ont pas été explorés. Par exemple, aucun de nos nodes sont en HA ou autre. J'espère pouvoir faire d'autres articles sur Prometheus en HA ou autre.
Évidemment, il s'agit ici de la stack de monitoring que j'ai exploré, mais rien ne nous empêche de faire votre propre expérience sur d'autres exporters ou d'autres TSDB.